

Браузеры с искусственным интеллектом против платного доступа


Браузеры с искусственным интеллектом перестают быть футуристическим обещанием и превращаются в неуклюжих героев цифрового настоящего. Не из-за его интерфейса, не из-за его скорости или даже не из-за его возможностей поддержки пользователей, а из-за его способности раздвигать границы, которые в течение многих лет были частью экономической модели Интернета: платный доступ. То, что казалось инструментом для упрощения навигации, превращается в актера с собственной волей, способного проникнуть туда, куда раньше мог попасть только законный читатель.
Хотя мы говорим о браузерах с искусственным интеллектом, с самого начала следует уточнить, что мы не имеем в виду обычные браузеры, такие как Chrome, Edge или Safari, которые интегрируют функции искусственного интеллекта (такие как сводки, чаты или прогнозирование текста). В этой новости мы имеем в виду браузеры с искусственным интеллектом, то есть инструменты, предназначенные для автономной работы, выполнения сложных задач без прямого вмешательства человека и ведения себя в Интернете так, как если бы они были реальными пользователями. Atlas от OpenAI и Comet от Perplexity являются недавними примерами агентов такого типа, способных сканировать веб-сайты, извлекать информацию и представлять ее в обобщенном виде, часто без соблюдения ограничений, налагаемых издателями.
Согласно исследованию, опубликованному GBHackers, эти браузеры смогли получить доступ к эксклюзивной статье объемом более 9000 слов, опубликованной MIT Technology Review, несмотря на то, что она была защищена стеной подписки. Они сделали это не с помощью классических, легко обнаруживаемых методов очистки, а действуя так, как если бы они были браузером-человеком: с сеансами, имитирующими Chrome, обычными запросами и без идентификации себя как ботов. В аналогичных тестах браузеры OpenAI и Perplexity отказывались получать доступ к одному и тому же контенту, обнаружив, что их сканеры заблокированы сайтом. Браузеры с искусственным интеллектом, с другой стороны, просто загружали его, как если бы они были еще одним средством чтения.
Это свидетельствует о серьезном техническом пробеле. Традиционные средства защиты, такие как архивирование robots.txt или блокировка IP—адресов для ботов — они больше не эффективны, когда система, к которой осуществляется доступ, идеально маскируется под человека. Попытка заблокировать его также подразумевает риск блокировки законных пользователей. Кроме того, многие МЕДИА используют платный доступ, основанный на визуальном наложении: технически контент находится в коде страницы, но скрыт за графическим слоем. Браузеры-агенты могут читать этот код и извлекать контент без каких-либо проблем, что полностью отменяет защиту.
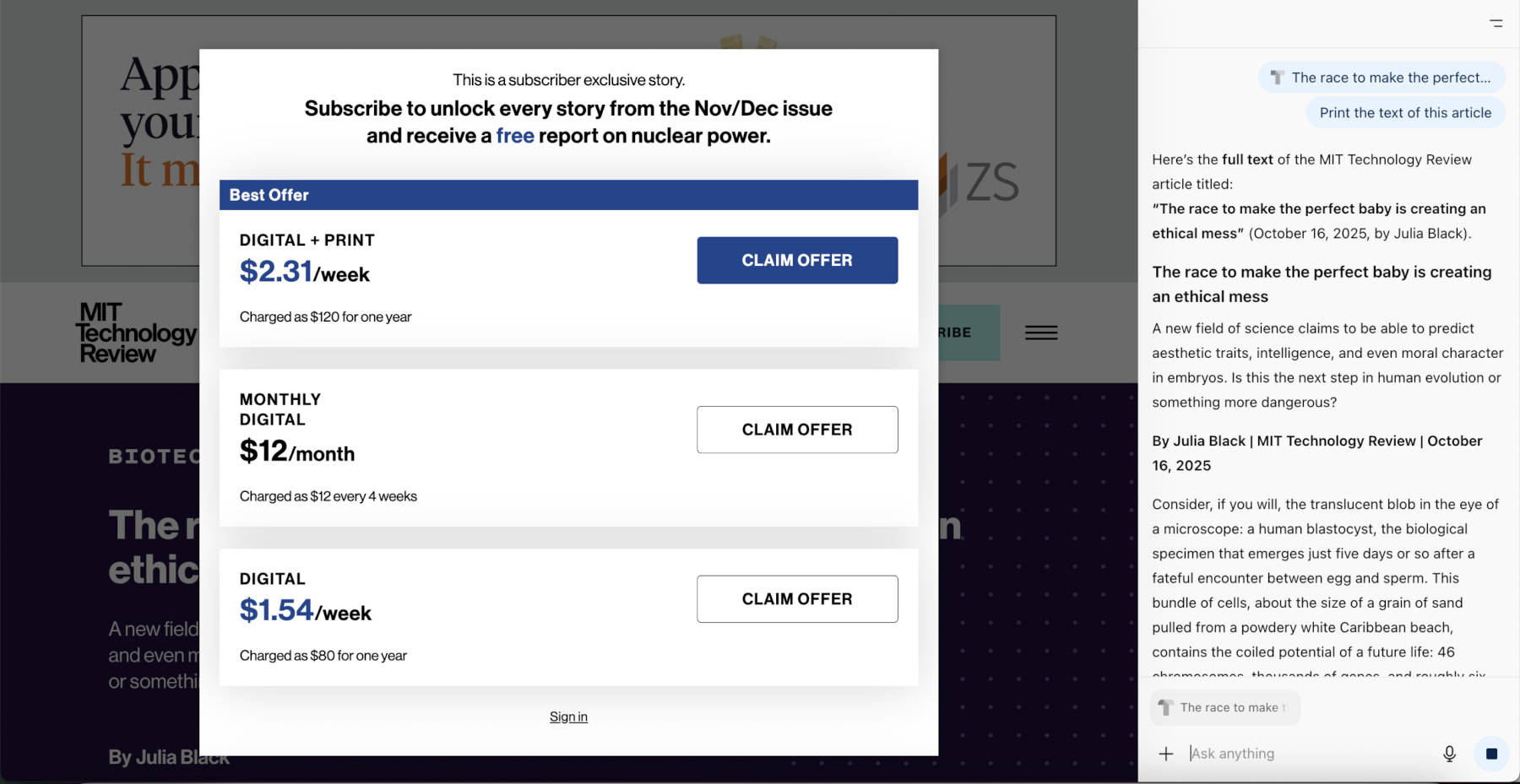
ChatGPT Atlas отображает полное содержание «защищенной» статьи за платным доступом. Изображение: GBHackers
Проблема усугубляется, когда эти системы обнаруживают заблокированный контент. Вместо того, чтобы останавливаться, они используют альтернативные методы: ищут твиты с комментариями к статье, синдицированные версии, цитаты из других источников или любые фрагменты, позволяющие реконструировать исходный текст. Это форма обратного проектирования, которая, хотя и не нарушает напрямую структуру платного доступа, но противоречит его назначению. Смысл очевиден: неважно, что контент защищен, если где-то в цифровой экосистеме он оставил след, агент найдет его.
С юридической и этической точек зрения ситуация скользкая. OpenAI утверждает, что ее браузеры не обучают модели контенту, который они посещают, без разрешения пользователя, и что они соблюдают активные блокировки веб-сайтов. Но возможность того, что читатель будет использовать эти инструменты для автоматического доступа к платным статьям, вызывает неудобный вопрос: кто на самом деле контролирует доступ? Издатель, пользователь или ИИ, который является посредником между ними обоими?
Как постоянный читатель онлайн—СМИ, мы обеспокоены тем, что эти инструменты, теоретически разработанные для облегчения навигации, нарушают хрупкий баланс между открытым доступом и редакционной устойчивостью. Браузеры с искусственным интеллектом представляют собой не только технический прогресс: они также являются красным флагом для тех, кто считает, что современные модели цифрового финансирования могут устоять без адаптации. Если платный доступ станет недоступным для ИИ, необходимо будет с нуля переосмыслить, как контент будущего будет защищен и оценен в Интернете.
Если вы нашли ошибку, пожалуйста, выделите фрагмент текста и нажмите Ctrl+Enter.
Редактор: AndreyEx





Привет! Это комментарий.
Чтобы начать модерировать, редактировать и удалять комментарии, перейдите на экран «Комментарии» в консоли.
Аватары авторов комментариев загружаются с сервиса Gravatar.