Как оценивать и сравнивать большие языковые модели (LLM)

Большие языковые модели (LLM) изменили наше взаимодействие с ИИ: от создания чат-ботов до генерации кода и решения сложных математических задач. Но по мере того, как эти модели становятся всё более совершенными, возникает важный вопрос: как на самом деле оценить их возможности и определить, какие модели действительно лучше?
Ответ заключается в контрольных показателях и системах оценки — систематических подходах, которые мы используем для тестирования, сравнения и понимания эффективности LLM. Важно понимать, как правильно оценивать LLM.
В этом блоге мы рассмотрим все, что вам нужно знать об оценке степени магистра права, от фундаментальных принципов хороших контрольных показателей до различных методик оценки, используемых на практике. Кроме того, мы также предоставляем блокноты с практическим кодом, которые помогут вам освоить выполнение оценок для реальных вариантов использования — мы видим, как наши клиенты работают над ними каждый день!
Почему важны тесты и оценки LLM
Основа прогресса
Бенчмарки служат ориентиром для развития и прогресса ИИ. Они позволяют нам ответить на фундаментальные вопросы: лучше ли Kimi-K2, чем Claude, справляется с задачами агентного кодирования? Насколько улучшились математические способности языковых моделей за последний год? Какая доработанная модель с открытым исходным кодом лучше всего справляется с вашими внутренними оценками?
Рассмотрим выпуск DeepSeek R1, который попал в заголовки благодаря своей конкурентоспособности по сравнению с передовыми моделями. Заявления компании были основаны не на субъективных впечатлениях, а на систематической оценке по шести различным тестам, включая AIME 2024, CodeForces, GSM8K и GPQA Diamond. Такое стандартизированное сравнение позволило сообществу ИИ-разработчиков быстро понять, на каком уровне находится DeepSeek R1 по сравнению с ранее выпущенными и зарекомендовавшими себя моделями, такими как o1 от OpenAI и серия Anthropic Claude.
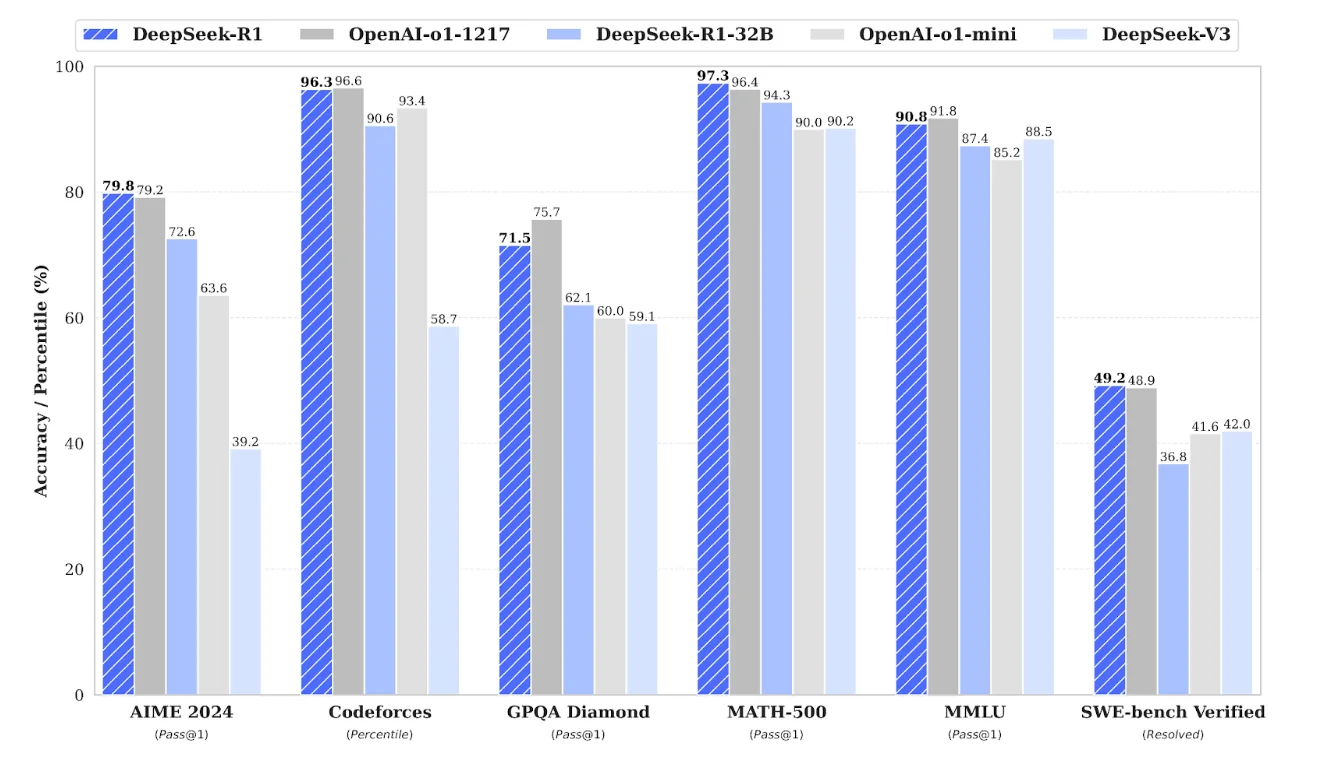
Источник: https://huggingface.co/deepseek-ai/DeepSeek-R1
Отслеживание революции в области искусственного интеллекта
Бенчмарки также помогают нам отслеживать более широкие тенденции в развитии ИИ. Возьмём, к примеру, бенчмарк MMLU, который проверяет знания по 57 предметам университетского уровня. Построив график производительности MMLU в динамике, мы видим, что в прошлом году мы преодолели этот интересный переломный момент: модели с открытым исходным кодом теперь не уступают по производительности системам с закрытым исходным кодом, а в некоторых случаях даже превосходят их, что знаменует собой значительный сдвиг в сфере ИИ.
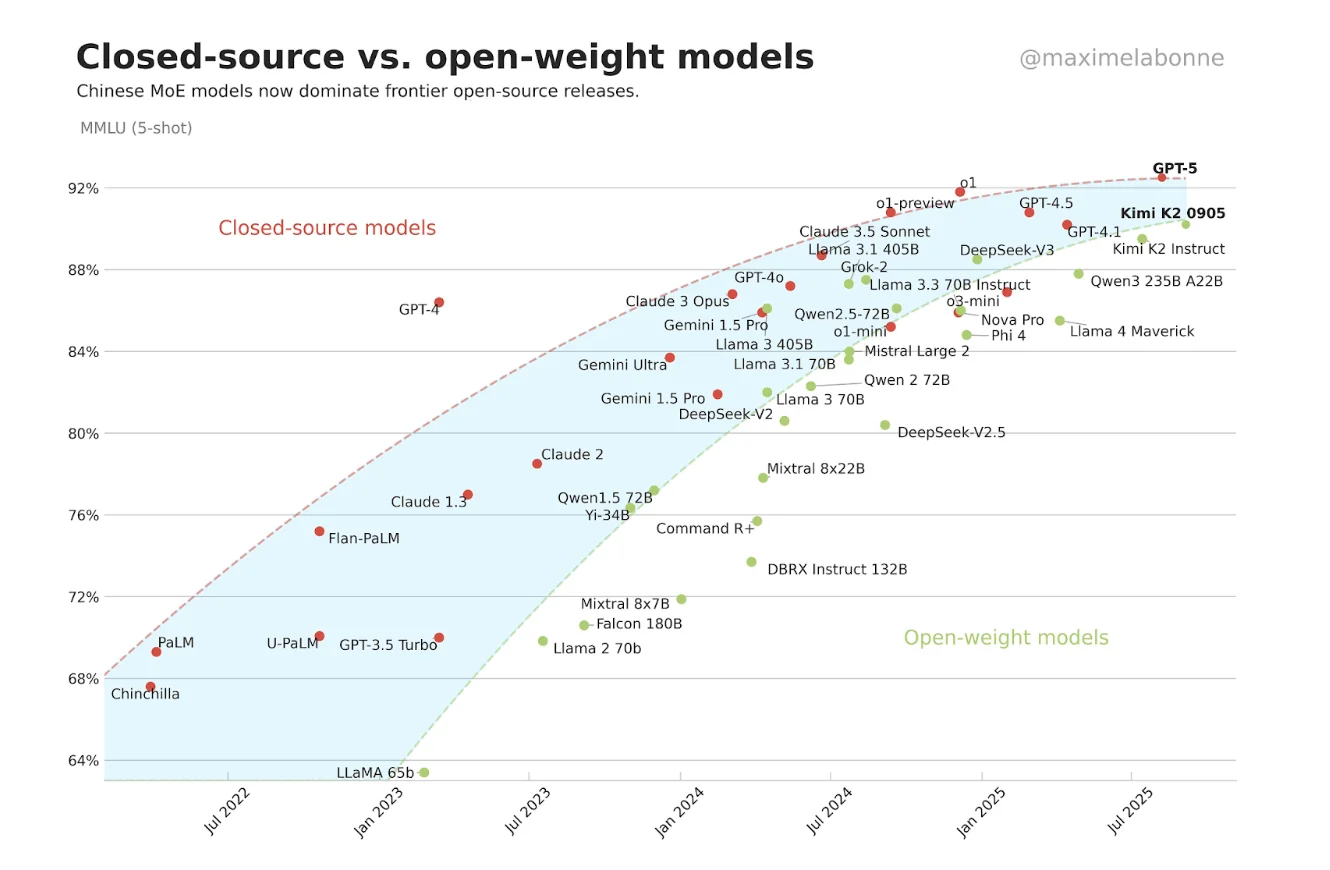
Источник: https://x.com/maximelabonne/status/1972615048511250647
Эта конвергенция не просто теоретический вопрос. Она имеет огромное значение для того, как организации внедряют ИИ, как исследователи получают доступ к передовым технологиям и как развивается вся экосистема ИИ.
Определение возможностей и ограничений
Пожалуй, самое важное: тесты помогают нам понять не только то, что могут делать модели, но и то, чего они не могут делать. Они выявляют «слепые зоны», указывают на области, требующие улучшения, и определяют приоритеты исследований. Это крайне важно для создания надёжных систем искусственного интеллекта и формирования соответствующих ожиданий от их применения в реальных условиях. Отличный пример — недавно выпущенные модели, которые демонстрируют снижение производительности в тестах на общие знания, таких как SimpleQA от OpenAI. Например, Qwen3 235B превзошёл многие другие модели по большинству показателей агентности и рассуждений, но при оценке общих знаний он сильно отстаёт! С тех пор ситуация исправилась благодаря новым версиям Qwen3 Instruct и Reasoning, которые значительно лучше справляются с SimpleQA.
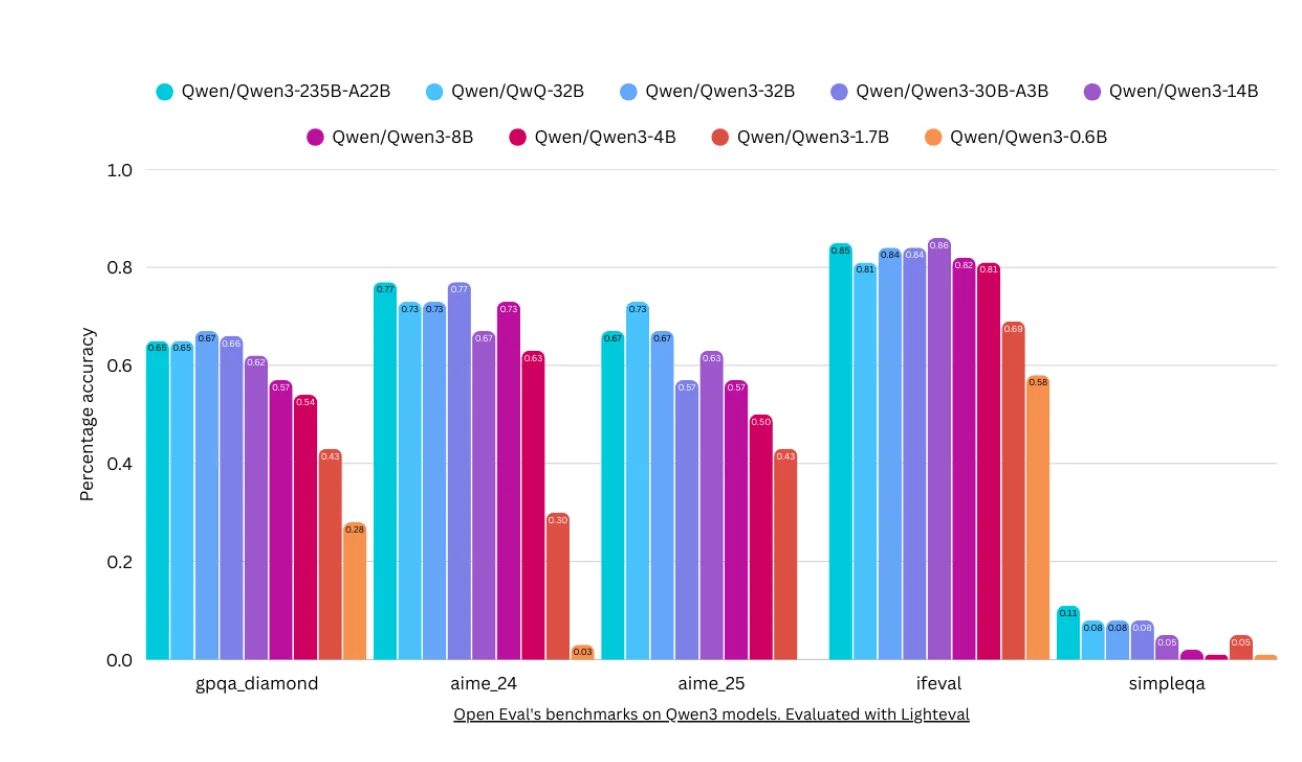
Источник: https://x.com/nathanhabib1011/status/1917230699582751157
Что делает бенчмарк LLM хорошим? Пять ключевых принципов.
Не все бенчмарки одинаковы. Наиболее ценные системы оценки обладают пятью ключевыми характеристиками, которые делают их надежными индикаторами возможностей модели.
1. Сложность: задача с движущейся мишенью
Хороший бенчмарк должен быть достаточно сложным, чтобы можно было отличить одну модель от другой. Это может показаться очевидным, но добиться этого сложнее, чем вы думаете. Рассмотрим MATH — бенчмарк, в котором представлены математические задачи соревновательного уровня (показаны зелёным на графике ниже). Когда он только появился, самые современные модели достигали точности в одну цифру — казалось, что эти задачи практически невозможно решить с помощью ИИ.
Если перенестись в сегодняшний день, то можно увидеть, что тот же эталонный тест позволяет моделям достигать точности более 90 %. То, что когда-то было отличительной чертой, стало нормой для современных систем. Это иллюстрирует феномен «насыщения эталонных тестов»: по мере совершенствования моделей ранее сложные тесты становятся простыми, и исследователям приходится постоянно разрабатывать новые, более сложные оценки.
Тенденция ускоряется, как видно на графике выше. Если моделям потребовалось почти четыре года, чтобы достичь высокой производительности на MMLU, то новые тесты, такие как GPQA (вопросы для докторантов), показали стремительный рост всего за год. Это ускорение отражает беспрецедентные темпы развития ИИ, которые мы наблюдаем, и подчёркивает важность всё более сложных тестов, которые помогают нам выбирать лучшие модели.
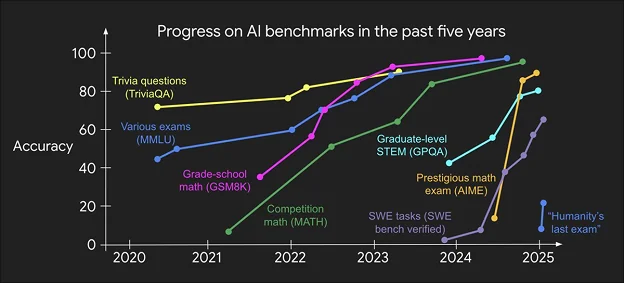
Источник: https://x.com/_jasonwei/status/1889096555254456397
2. Разнообразие: не ограничивайтесь тестированием одной области
Большие языковые модели — это системы общего назначения, которые люди используют для самых разных целей: от развлечений до работы и всего, что между ними, поэтому их оценка должна отражать эту широту возможностей. Тестирование только математических способностей может не выявить существенных ограничений в области здравого смысла или творческого письма. Платформа MixEval хорошо иллюстрирует этот принцип, показывая, как разные области — от естественных наук до социальной динамики — занимают разные области в пространстве оценки.
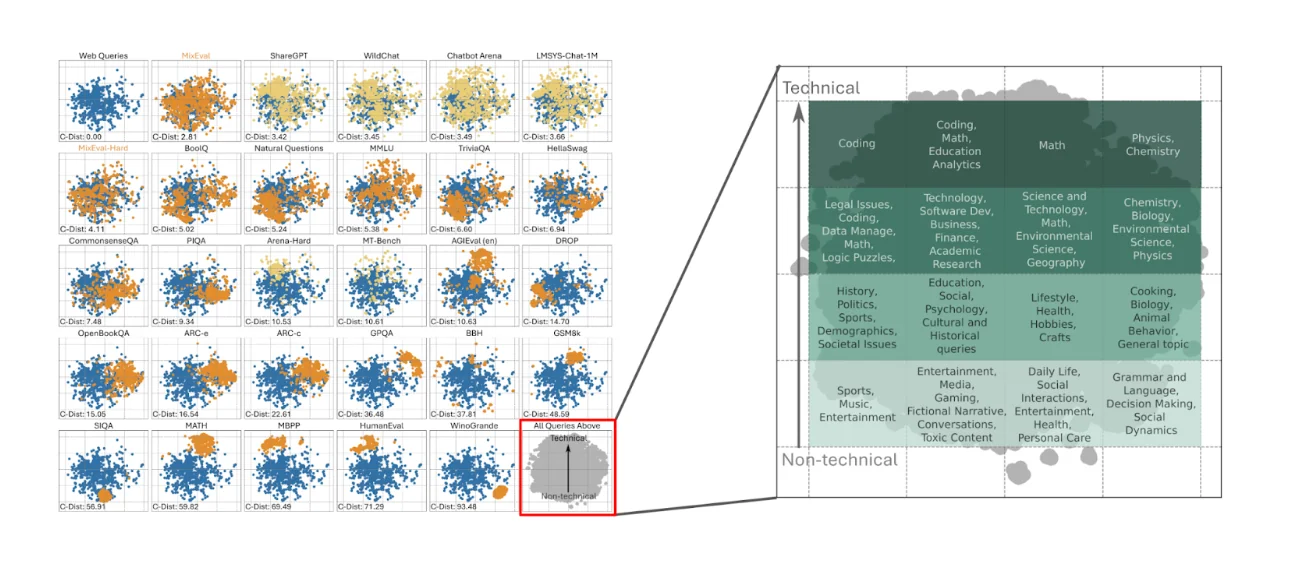
Источник: https://arxiv.org/abs/2406.06565
Это требование к разнообразию действует на двух уровнях. Во-первых, нам нужно несколько тестов, охватывающих разные возможности. Во-вторых, отдельные тесты должны содержать вопросы разных типов, чтобы модели, которые отлично справляются с определёнными шаблонами, но не обладают глубоким пониманием, не могли «обыграть» нас.
3. Полезность: сопоставление контрольных показателей с реальными сценариями использования ИИ
Тестирование может быть сложным и разнообразным, но если оно не связано с реальными приложениями, его ценность ограничена. Лучшие тесты проверяют возможности, которые либо напрямую важны для пользователей, либо служат основой для более сложных задач.
Возьмём, к примеру, тест GSM8K, который проверяет умение решать математические задачи. Почему это важно? Во-первых, это основа для более сложных задач, требующих количественного анализа, таких как финансовый анализ. Во-вторых, это напрямую помогает пользователям (студенты могут обратиться к ChatGPT за помощью в выполнении домашнего задания). В-третьих, это измеримый показатель более широких возможностей анализа, который помогает исследователям понять, действительно ли системы ИИ могут «думать» при решении задач.
Аналогичным образом HumanEval проверяет навыки программирования с помощью задач в стиле LeetCode. Этот тест полезен, поскольку навыки программирования пригодятся при создании программных агентов, помогут пользователям подготовиться к техническим собеседованиям и дадут представление о способности систем искусственного интеллекта преобразовывать естественный язык в точные инструкции.
4. Воспроизводимость: скрытая сложность
Одним из наиболее недооценённых аспектов качественных тестов является воспроизводимость. Одна и та же оценка должна давать одинаковые результаты при использовании разных реализаций и разными исследователями. К сожалению, добиться этого сложнее, чем может показаться.
Рассмотрим тест MMLU, в котором моделям предлагается выбрать один из четырёх вариантов. Это кажется простым, но на самом деле существует несколько способов проведения оценки:
- Исходный подход: предложите модели варианты A, B, C, D и сравните вероятность появления каждого токена
- Альтернативный подход: при сравнении вероятностей учитывайте все возможные токены
- Подход на основе последовательностей: сравните вероятность появления полного текстового описания для каждого варианта
Когда исследователи из разных организаций применили эти подходы, они получили разные результаты и оценки моделей. Это видно на приведённой ниже диаграмме, которая показывает высокую вариативность производительности при, казалось бы, незначительных изменениях входных данных. Такое несоответствие вызывает беспокойство, поскольку оно означает, что выводы о возможностях модели могут зависеть от особенностей реализации, а не от реальных различий в производительности.
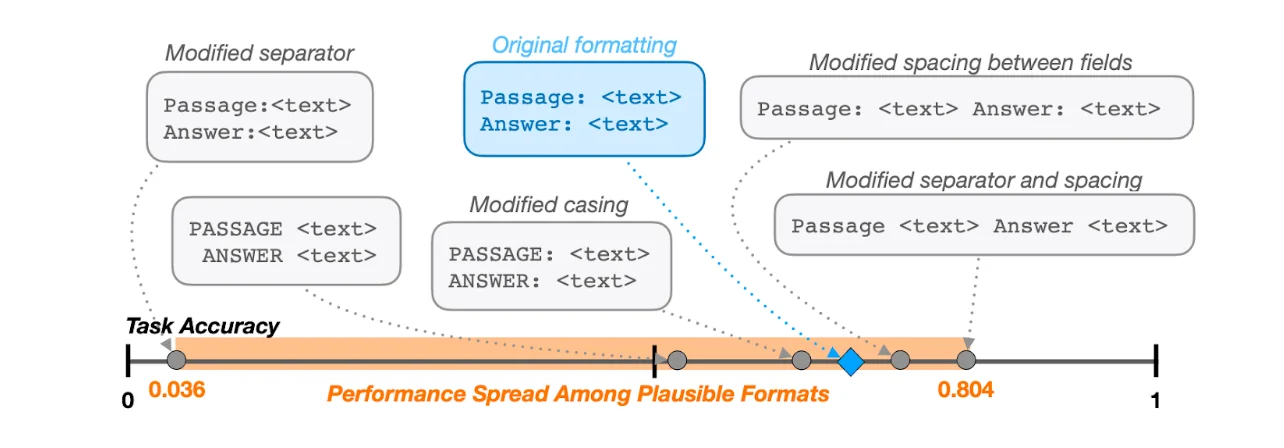
Источник: https://arxiv.org/abs/2310.11324
5. Загрязнение данных: невидимая проблема
Возможно, самой коварной проблемой при оценке LLM является загрязнение данных, когда контрольные вопросы появляются в обучающих данных модели. Современные языковые модели обучаются на огромном количестве интернет-текстов, потенциально включающих академические статьи, учебники и веб-сайты, содержащие контрольные вопросы.
Сравнение GSM8K и GSM1K прекрасно иллюстрирует эту проблему. GSM8K — это широко используемый набор математических задач, а GSM1K содержит аналогичные задачи, которые гарантированно являются новыми. Когда исследователи сравнили эффективность моделей на обоих наборах задач, они обнаружили, что многие модели набрали значительно меньше баллов на GSM1K. Это позволяет предположить, что высокие баллы на GSM8K могут частично отражать способность к запоминанию, а не к подлинному математическому мышлению.
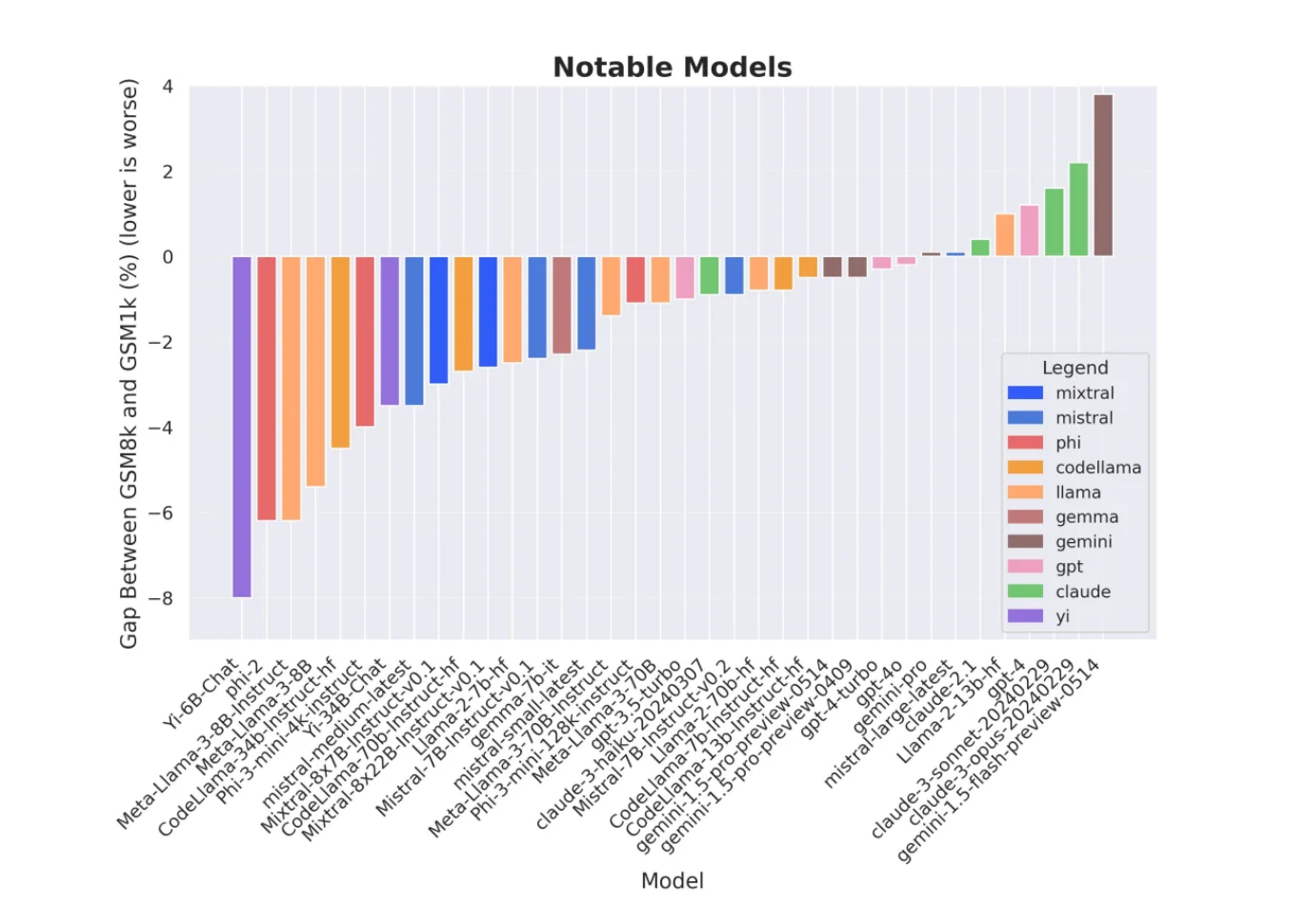
Источник: https://arxiv.org/abs/2405.00332
Эта проблема становится ещё более очевидной, если обратить внимание на искажение данных в тестах по математике. Когда модели SoTA были протестированы на математической олимпиаде в США (USAMO 2025) через несколько часов после её проведения (чтобы полностью исключить возможность искажения данных), даже лучшие на тот момент модели показали ужасающие результаты — менее 5%!
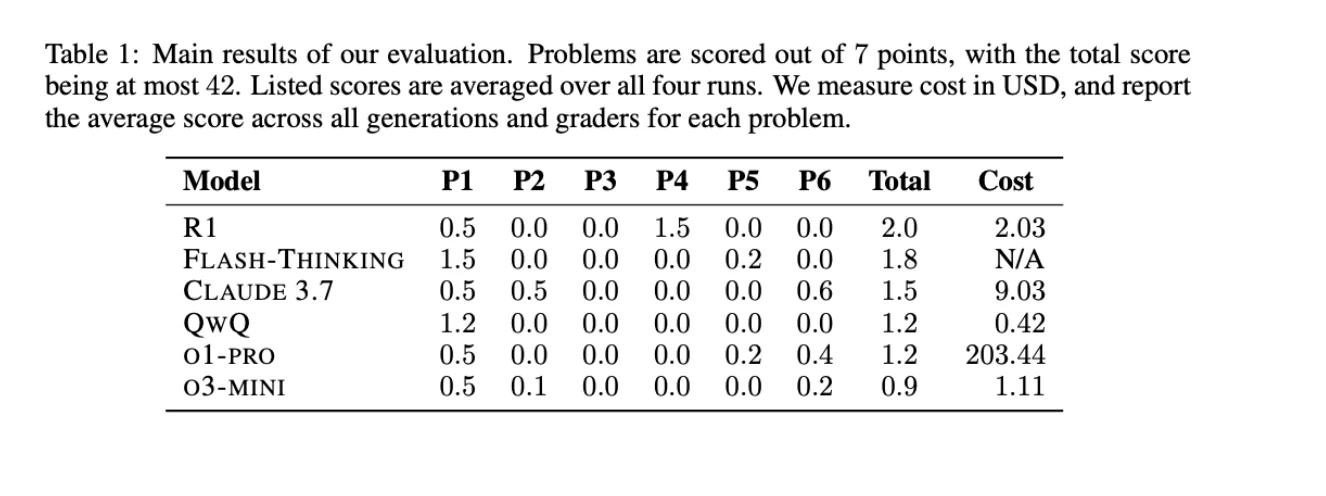
Источник: https://arxiv.org/abs/2503.21934v1
Эта проблема с загрязнением особенно актуальна для моделей и наборов данных с открытым исходным кодом, где вероятность перекрытия обучающих данных с тестовыми выше, а обнаружить это сложнее.
Типы методов оценки LLM
Оценка LLM включает в себя несколько различных подходов, каждый из которых имеет свои преимущества и подходит для определённых случаев.
Тесты на множественный выбор и классификацию
В самых простых оценках используются модели с вопросами с несколькими вариантами ответов или задачами на классификацию. Такие тесты дают чёткую и объективную оценку и их легко масштабировать. Вот несколько примеров:
- MMLU (Massive Multitask Language Understanding): проверка общих знаний
- HellaSwag: рассуждения, основанные на здравом смысле
- MATH: решение математических задач
Эволюция этих тестов демонстрирует интересную закономерность. Мы часто видим «семейства» тестов, в которых более новые версии заменяют старые по мере совершенствования моделей. На смену SWAG пришла HellaSwag, на смену GLUE — SuperGLUE, а на смену MMLU — MMLU-Pro (в котором было увеличено количество вариантов ответов, чтобы усложнить задачи).
Генерация и открытая оценка
Хотя вопросы с несколькими вариантами ответа легко поддаются оценке, они не отражают того, как мы на самом деле взаимодействуем с языковыми моделями. На практике мы просим модели генерировать ответы в свободной форме, поэтому оценка генерации крайне важна для понимания реальной эффективности. Вот несколько примеров:
- GSM8K (математика для начальной школы): проверяет пошаговое математическое мышление с автоматической проверкой ответов
- HumanEval: оценивает генерацию кода с помощью завершения функций с использованием тестовых примеров
- TruthfulQA: измеряет фактическую точность и устойчивость к галлюцинациям
Эти тесты компромиссны: они ближе к реальным сценариям использования, но при этом их проще оценивать. Легко отметить вопросы с несколькими вариантами ответа или математические задачи с готовыми ответами, но сложнее оценить все правильные шаги, которые привели к правильному ответу, или сравнить различные правильные способы решения задачи.
Оценка человека
Если мы хотим ещё больше усовершенствовать процесс оценки моделей в реальных условиях, мы можем обратиться к оценке, проводимой человеком, которая позволяет выявить нюансы, связанные с качеством, которые часто упускаются автоматизированными метриками. Однако здесь возникают проблемы с масштабированием и согласованностью.
LM Arena представляет собой золотой стандарт оценки человеком. Пользователи взаимодействуют с анонимными моделями и голосуют за лучшие ответы. Этот краудсорсинговый подход позволяет создавать рейтинги Эло, которые отражают реальные предпочтения пользователей в отношении различных запросов.
Сила «Арены» заключается в её масштабе: она собирает и систематизирует предпочтения миллионов пользователей в ходе обсуждений на самые разные темы. Однако запросы, как правило, носят скорее развлекательный характер, чем относятся к специализированным профессиональным задачам.
Специализированная человеческая оценка фокусируется на конкретных областях, таких как программирование Code Arena, разработка программного обеспечения (SWE-bench) или HealthBench. В таких оценках часто участвуют эксперты в предметной области, которые могут оценить техническую правильность и факторы качества, которые могут быть упущены обычными пользователями.
LLM в роли судьи
Использование языковых моделей для оценки других языковых моделей получило значительное распространение благодаря своей масштабируемости и гибкости. Этот подход сочетает в себе практичность оценок, репрезентирующих реальное использование, при этом сохраняя масштабируемость с использованием LLM — вместо людей для выполнения фактической оценки других LLM!
Alpaca Eval 2.0 использует GPT-4 в качестве судьи для оценки ответов модели по сравнению с эталонными ответами, предоставляя данные о частоте побед для различных моделей. Arena Hard отбирает сложные запросы из Chatbot Arena для создания сложного набора данных для оценки. Многоэтапные тесты оценивают способность к диалогу в ходе длительных взаимодействий.
Главным преимуществом LLM-в-роли-судьи является возможность настраивать критерии оценки. В отличие от фиксированных показателей, вы можете поручить судье оценивать конкретные аспекты, такие как техническая точность, понятность для новичков или использование отраслевой терминологии.
Однако у этого подхода есть существенные ограничения. Судейские модели, как правило, отдают предпочтение более длинным ответам, независимо от их качества, и часто демонстрируют предвзятое отношение к ответам моделей из своего семейства (модели GPT предпочитают ответы GPT и т. д.). Для получения достоверных результатов необходимы правильная калибровка и коррекция предвзятости. Примером может служить контроль стиля, добавленный в LM Arena.
Рекомендации по надёжной оценке LLM
Для эффективной оценки LLM необходимо использовать несколько взаимодополняющих тестов, а не полагаться на какой-то один показатель, поскольку разные тесты отражают разные аспекты возможностей модели. Сопоставляйте критерии оценки с реальными сценариями использования: если вы создаёте чат-бота для обслуживания клиентов, отдавайте предпочтение полезности и умению вести диалог, а не творческому письму или математическим рассуждениям. Учитывайте риски, связанные с искажением данных, используя новые наборы тестов и интерпретируя результаты с должной долей скептицизма.
Для производственных систем внедрите системы непрерывной оценки, чтобы отслеживать производительность с течением времени, поскольку модели могут давать сбои из-за изменений в поведении пользователей, распределении данных или обновлениях. Проведите A/B-тестирование с участием реальных пользователей, чтобы убедиться, что улучшения в контрольных показателях действительно приводят к повышению качества обслуживания, и установите чёткие критерии для переобучения или замены, когда производительность падает ниже приемлемого уровня.
Оценка больших языковых моделей — это и искусство, и наука, требующая тщательного подхода не только к тому, что измерять, но и к тому, как делать это надёжно и осмысленно. По мере того как языковые модели становятся всё более мощными и распространёнными, надёжные системы оценки приобретают всё большее значение. Сфера оценки стремительно развивается, постоянно появляются новые эталоны и методологии, но основные принципы остаются неизменными: используйте разные точки зрения, согласовывайте оценки с реальными потребностями и сохраняйте здоровый скептицизм в отношении любой отдельной метрики. Главный вопрос заключается не в том, могут ли модели пройти наши тесты, а в том, достаточно ли сложны наши тесты, чтобы гарантировать безопасное и эффективное использование этих систем по назначению.
Редактор: AndreyEx




